Naming a Concept Isn't the Same as Locking It
- #encode
- #building-in-public
- #cs50p
- #learning-systems
Sat down today for the first real run of a session template I’d designed three days ago. Seventy-five-minute compound: warm-up vocab drill, video learning block, memory work, closeout. Clean shape on paper. The first thing I did was scrap the warm-up.
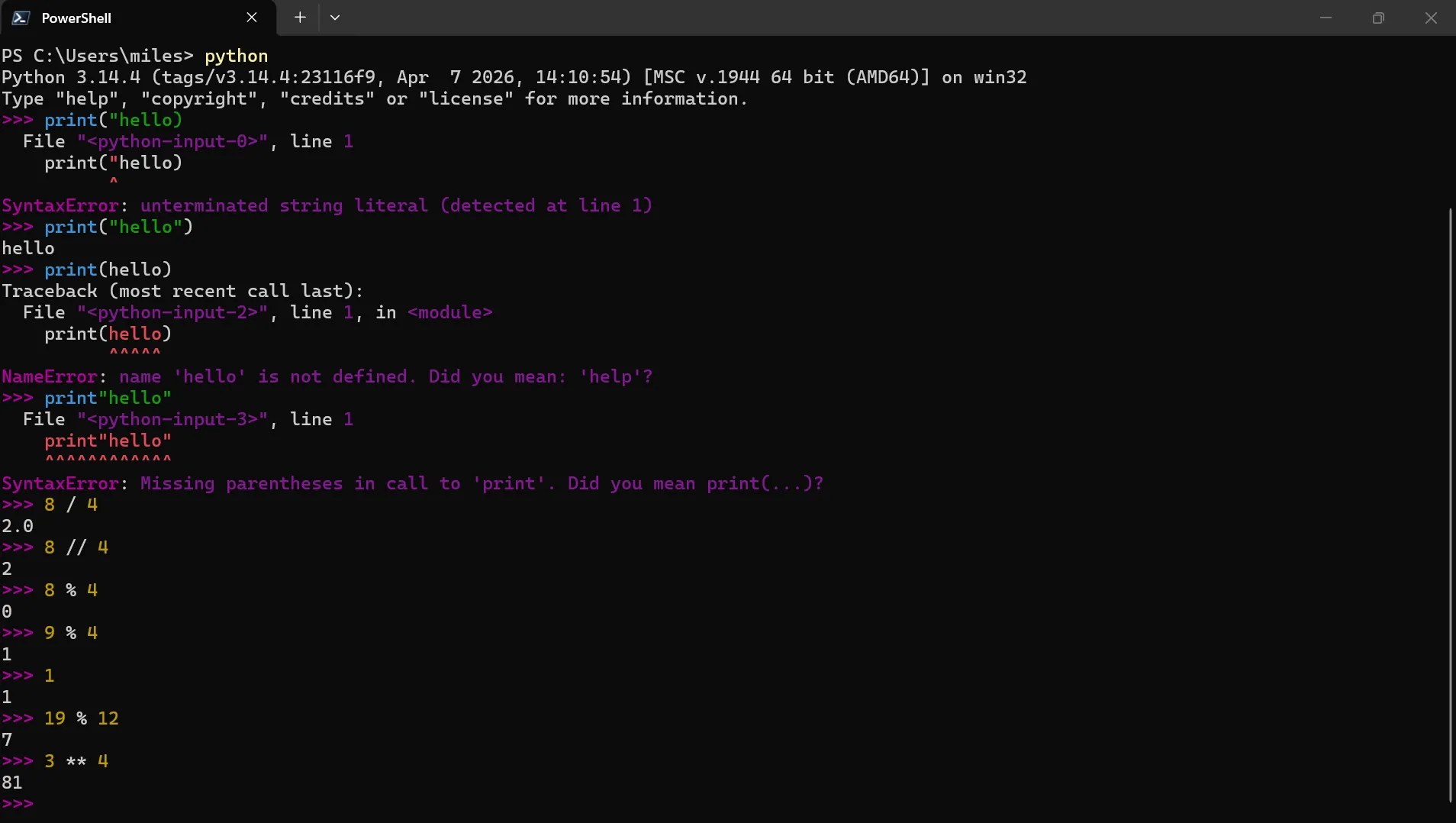
Started Block 1 the way the template said. Open the Python REPL, lock the canonical print("hello"), then deliberately break it three ways and read each error. The drill ran in thirteen minutes — one of the breaks by accident, since I’d typed print("hello) with a missing close-quote at the lock attempt and gotten the unterminated-string error before I’d even started the deliberate ones. The breaks themselves did what they were supposed to do. print(hello) returned a NameError, because without quotes Python looks for a variable called hello, finds nothing, and helpfully suggests help. print"hello" returned the missing-parentheses SyntaxError, because naming a function isn’t the same as calling it. Three structural rules came out of fifteen minutes: quotes mark data versus name, parens are the call signal, quotes are paired boundary markers.
Then I told the assistant to throw the rest of Block 1 out. The vocab-drill format generates friction I don’t need before I’m warm. Forty-five minutes of video learning instead, find the flow inside that window. That call held — Block 1 redesigned mid-session became Section 14 (Style) and Section 15 (Integers and Operators) at concept-pace. Six ideas with a quick restate-it-back after each. Six for six on the restates. Style is for humans, not Python. PEP 8 is a rulebook, not a function. Chained method calls versus separated lines is a programmer choice with a debug-versus-brevity trade-off. Integers are whole numbers. Math operators are the ones you already know. Modulo gives you the remainder. Each one I could put back in my own words. Surface looked clean.
Then I asked for the test.
I did not need to ask for the test. The plan had memory work for that block — a palace rebuild and a day-one cold test I’d been putting off. I was in good flow, didn’t want to break it, repurposed the slot for fifteen minutes of active recall on what we’d just covered. The cost of that swap is real and gets logged elsewhere. The test happened.
Question one was easy. Style is for humans, Python doesn’t enforce, fixing style makes the code easier to read. Pass. Question two asked me to name one specific PEP 8 rule and one tool that auto-enforces. I gave two wrong answers across two attempts. I named a topic from a different concept as the rule, and I named the Python interpreter as the enforcement tool — the exact thing we’d just covered as the thing that does NOT enforce style. Question three through four I passed clean. Question five was a REPL prediction: predict 8 / 4, 8 // 4, and 8 % 4 before running them. I predicted two for all three. The actual answers were two-point-zero, two, and zero. Two of the three predictions were wrong on operators I had just been taught. I’d given the same number for three different operators because my mental model had collapsed into “it’s eight divided by four, the answer is two.” The operators evaporated.
Naming a Concept Isn’t the Same as Locking It
That’s the lesson of the day. Surface lock — being able to name a concept and recite its abstract framing — and deep lock — being able to predict what it produces under specific input — look identical in conversation. They do not look identical under test. The test is what makes the difference visible.
A competitor recognizes the shape immediately. A rookie can describe a play in the locker room cleanly. They draw it on the whiteboard, name the assignments, name the reads, the position coach nods. Surface lock. Then the snap fires and the pre-snap read shifts by a half-step from what they rehearsed and they freeze. The play they “knew” doesn’t fire under pressure. The fix in sports is reps under increasing pressure: film, walkthrough, full-speed practice, scrimmage, game speed. Each level forces a deeper encoding because the failure modes differ. Skip a level and you’re operating at the previous level’s depth, even when you sound fluent.
The same gap exists in learning to code. Watching the lecture locks the surface. Restating it in your own words locks a little deeper, but it’s sycophancy-prone — the brain says “I get it” because saying “I don’t” is uncomfortable, not because the concept is actually locked. Predicting an output and being wrong locks much deeper, because reality returned a number that contradicted the model and the brain has to update. “Make sense?” is a check-in that produces no data. “Predict eight modulo four before pressing Enter” is a check that produces honest data. The REPL doesn’t know how to be polite.
The cheapest move from here is to never close a concept beat without a prediction-and-verify cycle. I’d been treating restates as the lock, and restates are surface evidence at best. The prediction step is where the encoding actually deepens — not from being right, but from being wrong and getting corrected in the same minute the gap formed.
Half the answers wrong on operators I’d just covered is the day’s data. Next session opens with the four lock failures back on the board, and every concept beat after that closes with a prediction step before we move on.